
方案概述
秦皇岛银行AI+数据分类分级项目是以数据为核心,面向全行数据进行AI自动化数据分类分级。通过梳理并标识数据,实现在复杂环境下自动化扫描客户数据并识别其包含的相关业务信息,并借助AI大模型实现自动化分类分级,实现对业务的零打扰。针对结构化数据,可基于库表字段命名、数据特征等进行灵活打标,直接生成表级、字段级分类分级结果。通过接入本地化部署通义千问大模型,能够进一步突破传统规则的局限,基于智能引擎的深度学习,理解字段语义与数据关系,动态优化分类策略,使识别准确率提升到90%以上。
方案背景
随着数字化转型的加速,金融行业面临着数据安全和隐私保护的挑战。我国《数据安全法》、《个人信息保护法》等制度体系不断完善,数据分类分级已从单一监管要求演进为金融机构构建数据安全能力体系的基础工程。随着海量数据的不断产生、传输、存储和应用,面临着来自黑客攻击、内部人员恶意泄露以及数据误操作等多重安全威胁的侵。因此,秦皇岛银行加快构建数据安全治理体系,确保数据的安全性和合规性。
数据安全分类分级是数据安全的基础。从财务数据到客户个人隐私信息,并非所有数据都拥有相同的敏感度和重要性,不同业务数据在敏感性和价值上存在着显著的差异。只有精准地识别各类数据的安全等级,才能制定合适的安全防护措施,从而有效保障数据安全。
方案目标
AI+数据分类分级项目的目标是构建健全的数据安全治理体系,通过接入本地化部署通义千问大模型,自动化完成数据资产盘点、数据分类分级等工作,快速构建统一视图的敏感数据目录,并且能够实现敏感数据目录与数据保护技术无缝衔接,快速落地敏感数据保护技术措施。
方案特点
AI+数据分类分级项目通过接入本地化通义千问大模型辅助进行数据分类标注,极大增强上下文语义理解能力,显著提升自动化处理效率,保障分类分级的准确性和持续优化。通过实时、高频的更新机制,屏蔽分散、异构数据源的差异和复杂性,构建一个多源异构数据统一视图,形成统一的敏感数据目录可视化视图。
方案业务流程图
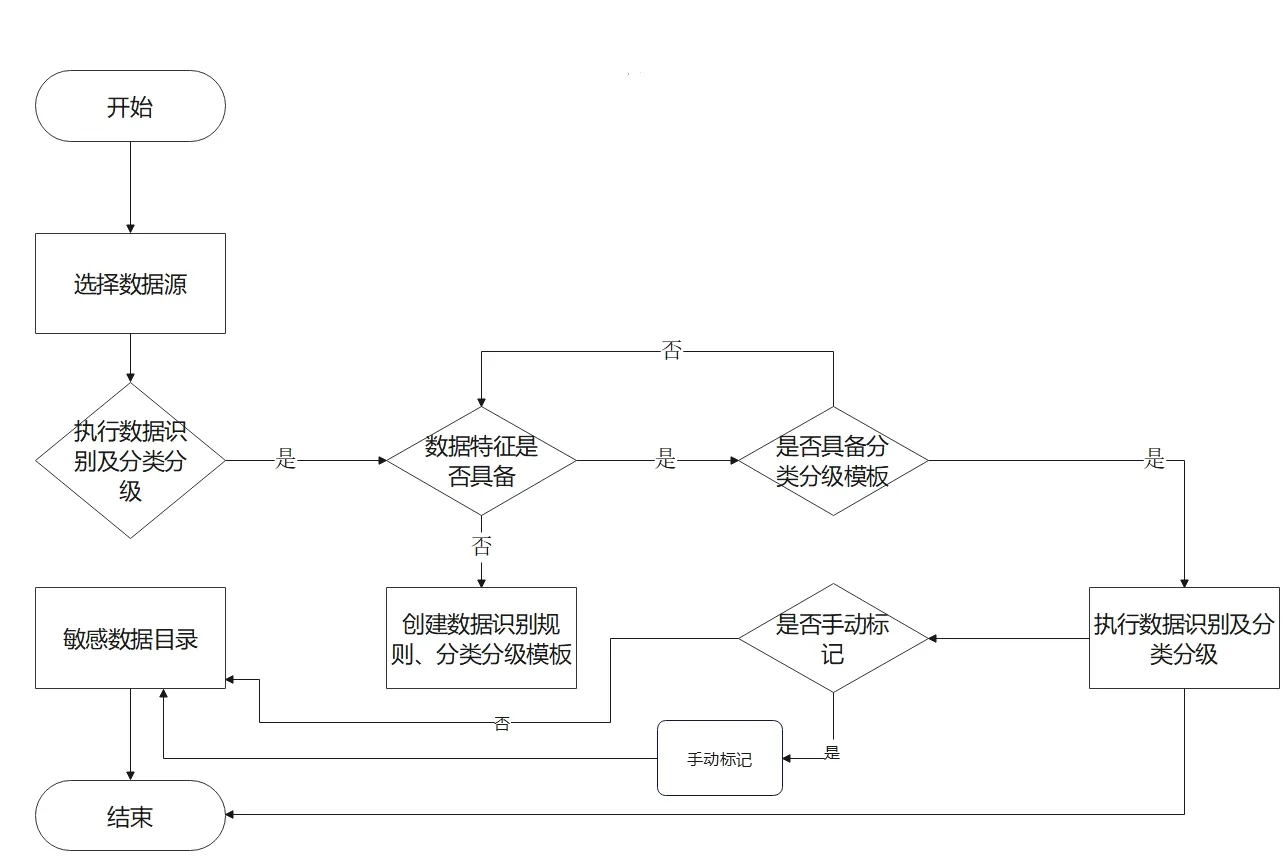
图1 敏感数据识别及数据分类分级流程图
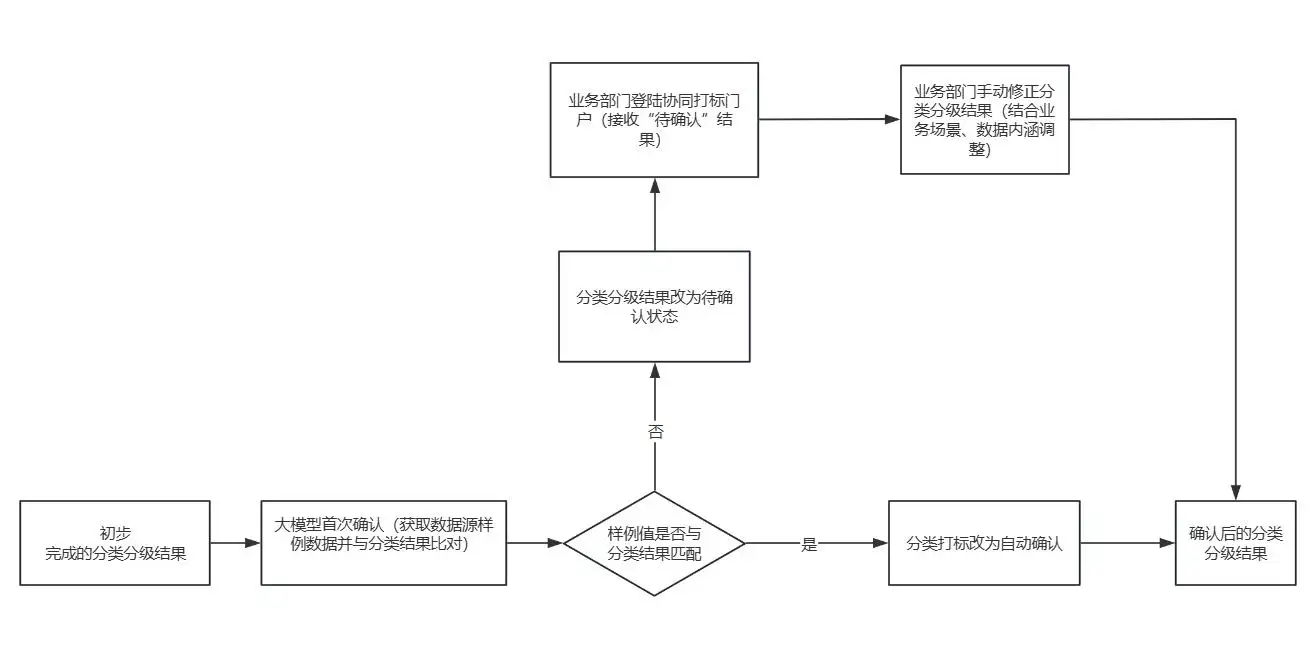
图2 数据分类分级结果打标准确率校验流程
实现功能展示

图3 AI数据分类分级项目功能架构图
基础设施层:平台运行的基础支撑,为整个系统提供硬件(如芯片/CPU)和基础软件(如数据库、中间件、操作系统)等资源,并且能够适配各类信创组件,保障平台稳定运行。
对接数据源层:主要负责与行内的业务源系统进行连接,获取所需的结构化数据,为后续的数据标注、分类分级等操作提供基础。
平台功能层:数据分类分级相关的核心能力建设,像数据识别、分类分级处理、协同打标以及数据可视化等关键功能都在此层实现,是完成分类分级工作的核心环节。
业务应用层:面向用户,将平台功能以直观的前端操作菜单形式呈现,用户可通过这些菜单便捷地开展资产管理、数据发现、分类分级扫描以及查看数据目录等业务操作。
方案案例及效果
AI+数据分类分级项目借助自动化和智能化的手段,能够迅速且准确地完成数据安全分类分级工作,实时洞察企业敏感数据资产,从而显著减少了人工操作的时间和人力成本。
与传统的数据安全分类分级方法相比,基于智能分类分级引擎,无需对字段实例进行大量的扫描计算,从而大幅降低了计算资源的消耗,低成本实现数据安全分类分级成果与数据保护技术措施无缝衔接,为企业节省了运营成本,显著增强了数据的安全性与合规性。智能分类分级引擎能够精准地识别出含有敏感信息的字段,如个人身份信息、金融交易数据等,并对其进行适当的分类和有效保护,保护了企业的数据安全,降低了因数据泄露或滥用而引发的法律风险。
方案未来展望
展望未来,通过引入AI大模型进行数据安全治理的前景将更加广阔。除了智能化数据分类分级外,还可以广泛应用于数据质量规则自动推荐、数据模型优化、数据模型生命周期管理优化等多个领域,为数据安全治理提供更加全面和深入的支持,助力金融机构在数字化浪潮中稳健前行。