
方案概述
在当今软件工程领域,随着微服务架构与敏捷开发的普及,单元测试作为质量保障的基石,其重要性不言而喻。然而,传统的手工编写单元测试不仅耗时费力,而且往往难以覆盖复杂的边界条件与异常场景,导致代码质量难以量化保障。本方案提出了一种创新的 “单元测试代码生成方法、系统、设备及介质”,旨在解决这一核心痛点。该方案深度融合了以大语言模型为核心的生成式 AI 技术与传统的静态代码分析技术,构建了一套覆盖全生命周期的自动化测试生成体系。其核心设计理念在于打破单一模型生成的局限性,通过引入覆盖率加权检索(Coverage-Weighted Retrieval)与Agent 智能体协同机制,实现了从源码解析到测试用例闭环验证的智能化飞跃。
本方案的总体技术路线依托于先进的 “检索增强生成”(RAG)架构,并在此基础上进行了深度优化。首先,系统对目标工程代码进行深度结构化解析,生成包含抽象语法树(AST)与依赖关系的元信息集合。随后,利用覆盖率加权相似度算法,从历史测试用例数据库中精准召回高覆盖率且语义相关的样本。这些高质量样本被动态注入到PromptBundle数据包中,作为大模型的上下文输入。更为关键的是,本方案引入了 Agent 智能体作为核心编排中枢,将复杂的测试生成任务拆解为 “测试类生成”、“功能用例生成”、“异常边界生成” 及 “覆盖率优化” 等多个原子候选单元测试代码生成子任务,分别调用专用的垂类模型进行并行处理。
为了确保生成的测试代码不仅 “可编译” 而且 “有效”,本方案构建了严密的闭环反馈(Closed-loop Feedback)机制。通过 IDE 插件与 CI/CD 流水线的无缝联动,系统能够自动捕获本地运行的编译错误、断言失败及覆盖率不足等信息,并将这些反馈回灌至 Prompt 模板中进行迭代修复,直至达到预设的质量标准。这种 “生成—验证—优化” 的自动化闭环,极大地降低了人工干预成本,显著提升了测试代码的平均行覆盖率与异常用例命中率。
方案背景
当前,软件测试行业正处于从手工测试向智能化测试转型的关键十字路口。在 “背景技术” 的深入调研中,我们发现现有的单元测试代码生成方法主要分为两大流派,但均存在显著的内生缺陷,难以满足企业级应用的高标准需求。
1、行业现状与主流路径缺陷
第一类是模板驱动法。这种方法依赖于预定义的固定测试框架与代码模板,虽然在一定程度上规范了测试结构,但其本质是静态且僵化的。开发者仍需手动填充大量的业务逻辑代码,导致自动化程度低。其核心缺陷在于缺乏灵活性,难以应对复杂多变的业务逻辑,且对多语言环境的适配成本极高,无法真正解放生产力。
第二类是单模型驱动法。随着大模型的兴起,利用单一通用大模型直接生成测试代码成为热门尝试。然而,这种 “端到端” 的黑盒模式在实际工程中暴露出了严重问题:
覆盖率不足: 通用模型往往倾向于生成 “Happy Path”(正常路径)代码,而忽略复杂的边界条件与异常场景,导致生成的测试用例覆盖率低下。
幻觉问题(Hallucination): 由于缺乏项目特定的上下文理解,单模型容易引用不存在的 API、错误的依赖包或错误的业务逻辑,导致代码无法编译或运行。
不稳定性: 单一模型的输出具有随机性,缺乏有效的约束与后处理机制,导致生成的代码质量波动大,鲁棒性差。
2、BizDevSecOps 时代的驱动力
在 BizDevSecOps(业务、开发、安全、运维一体化)理念日益深入人心的今天,企业对研发效能与安全合规提出了双重挑战。传统的测试生成方法无法满足全生命周期的自动化需求,尤其是在金融、电信等关键基础设施行业,对 “源代码不出域”、“数据隐私安全” 有着严格的红线要求。依赖公有云大模型的方案天然存在数据泄露风险,难以落地。此外,持续集成(CI)流水线要求测试代码必须具备高通过率与低维护成本,任何需要大量人工修复的自动化方案都将被边缘化。
因此,本方案应运而生。我们提出的改进方向直击上述痛点:通过多模型协同解决单模型的盲区,利用历史检索增强解决上下文缺失,构建本地化闭环保障数据安全与合规。这不仅是对现有技术的修补,更是一次架构层面的重构,旨在打造一个真正 “懂业务、高覆盖、自进化” 的智能单元测试生成系统。
方案目标
本方案旨在构建一套全自动化、高可靠性且具备自我进化能力的单元测试生成系统,具体目标设定如下:
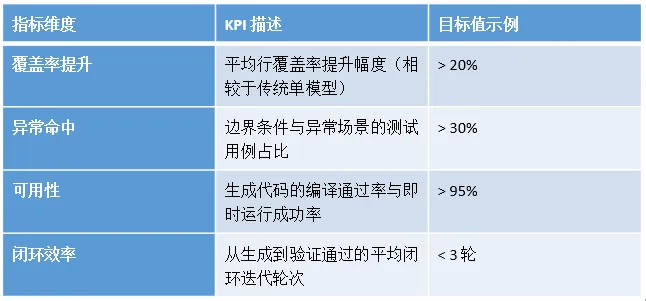
覆盖率目标(Coverage Assurance): 核心目标是显著提升代码覆盖率。不仅要求全工程的平均行覆盖率达到行业领先水平(如>80%),更强调对分支覆盖、异常路径及边界条件的精准命中。通过覆盖率加权检索算法,确保生成的测试用例不留死角。
质量与稳定性目标(Stability & Robustness): 提升生成代码的 “一次通过率”。目标是大幅降低生成代码的编译错误率与运行失败率,减少人工介入修改断言或依赖的频率。生成的代码应具备生产级质量,能够直接合入主干分支。
自动化与闭环目标(Automation Loop): 实现 “生成—验证—修复” 的全无人值守闭环。系统应能自动解析运行日志,自动识别失败原因,并自动触发 Agent 进行修复,直至用例通过。目标是将闭环收敛轮次控制在低位(如平均 3 轮以内),并显著降低 CI 集成时延。
合规与安全目标(Compliance & Security): 满足金融级安全合规要求。支持全链路本地化部署,确保源代码、历史用例库及运行时数据完全不出内网,彻底杜绝数据泄露风险。
关键性能指标(KPI)示例
方案特点
本方案区别于传统方法的根本特征在于其系统化的协同机制与动态优化能力。通过将静态分析、向量检索与生成式 AI 深度解耦又有机融合,实现了 “1+1>2” 的效果。
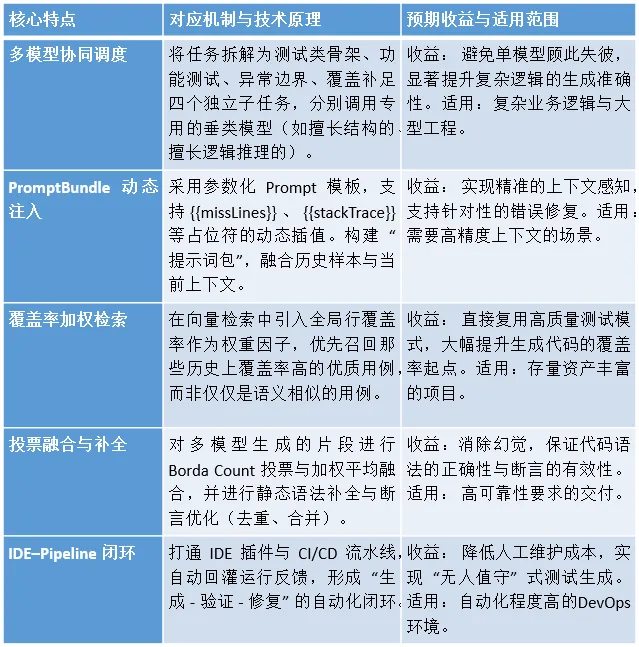
其中,动态权重调节机制是本方案的一大亮点。系统能够根据历史样本的缺陷密度、执行耗时、变更频率等指标,动态计算权重因子,并据此调整检索算法中的相似度参数($\gamma$和$\theta$)。这意味着系统具有 “记忆” 和 “学习” 能力,能够随着项目的演进,越来越精准地推荐最适合当前代码风格的测试范式。
方案业务流程图
业务流程图:

本方案的业务流程设计严密,涵盖了从源码解析到最终合入的全过程。整体流程可划分为 “初始化解析”、“智能生成与融合”、“闭环验证与反馈” 三个核心阶段。
场景时序图:

流程概览与详细步骤
第一阶段:解析与检索
流程始于对目标工程代码文件的深度解析。系统通过 IDE 接口解析 AST 与程序结构,提取类名、方法签名及依赖关系,构建出结构化元信息集合。同时,结合覆盖率引擎数据,生成结构化上下文特征向量。 随后进入核心的检索环节。系统利用覆盖率加权相似度检索算法,在历史测试用例数据库中寻找最佳匹配。这里不仅计算代码的语义相似度,更结合历史用例的 “全局行覆盖率” 进行加权,确保召回的样本不仅 “长得像”,而且 “质量高”。
第二阶段:Agent 编排与生成
Agent 智能体接管任务,进行精细化的任务分解。它将生成任务拆解为测试类骨架生成、功能测试、异常边界测试等子任务。针对每个子任务,Agent 会构建专属的PromptBundle,将检索到的历史高优样本与当前代码上下文填充进 Prompt 模板。 系统随后并行调度多个专用大模型。例如,一个模型专注生成骨架,另一个专注挖掘边界条件。如果模型置信度低,系统会自动触发补充检索策略,扩大检索范围或更换 Embedding 模型,确保输入质量。
第三阶段:融合、验证与闭环
多模型生成的片段汇聚到融合引擎,通过投票机制(Borda Count)与断言去重优化,整合成一份完整的候选单元测试代码。 随后,代码进入本地运行验证环节。系统自动编译并运行测试,采集执行日志与覆盖率数据。如果发现编译错误或覆盖率未达标(例如<80%),系统会将具体的错误堆栈或未覆盖行号回灌给 Agent。Agent 据此利用 LoRA 插件或 Re-Prompt 机制进行针对性修复,直到满足质量标准或达到最大迭代次数。最终,通过验证的代码将自动推送到 CI/CD 流水线,完成集成。
实现功能展示
安装:
配置:
触发(支持按指定类或方法):
运行结果:
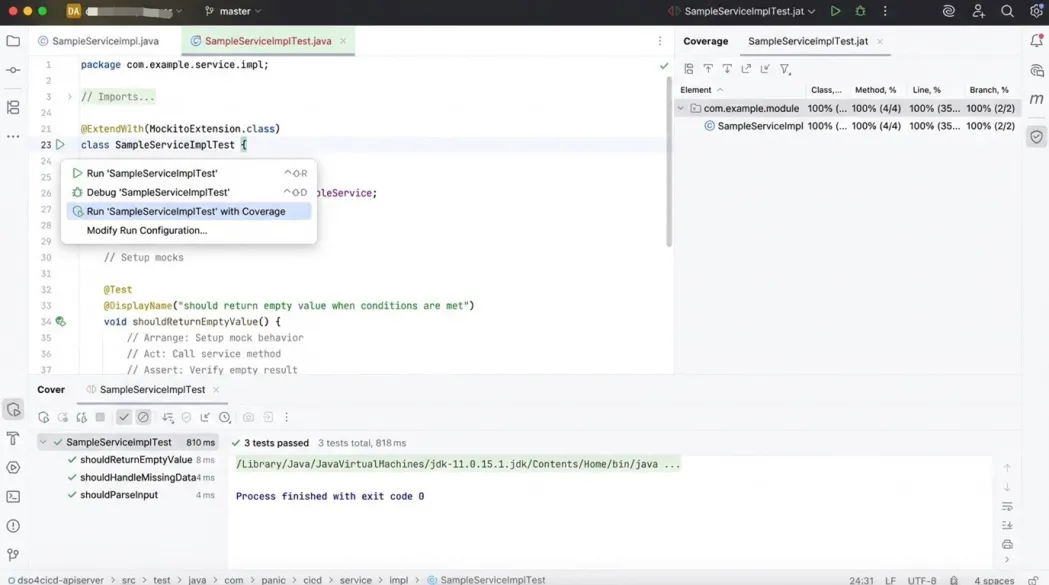
覆盖率统计:
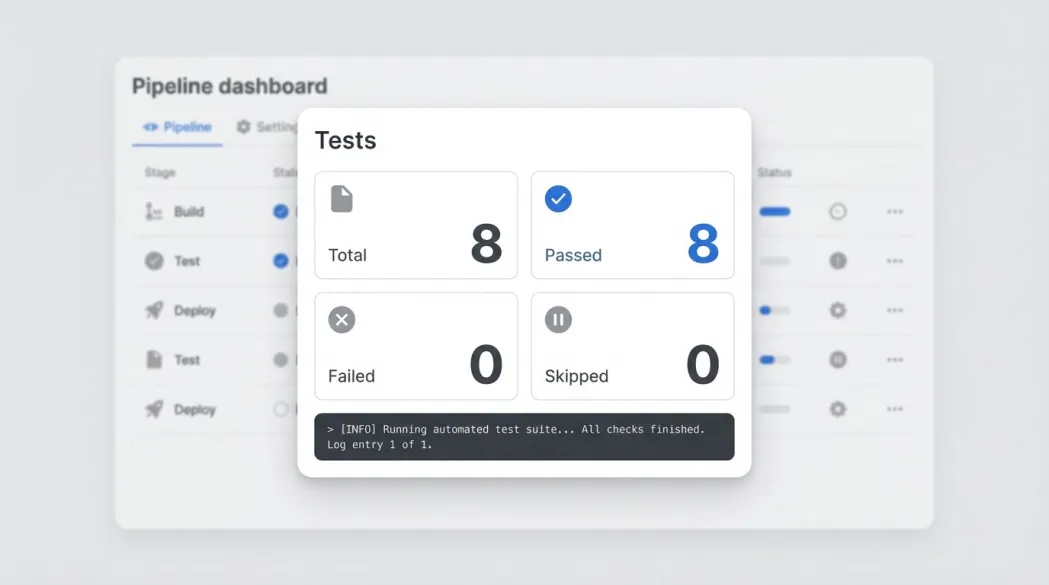
与行内CI/CD集成效果示例:
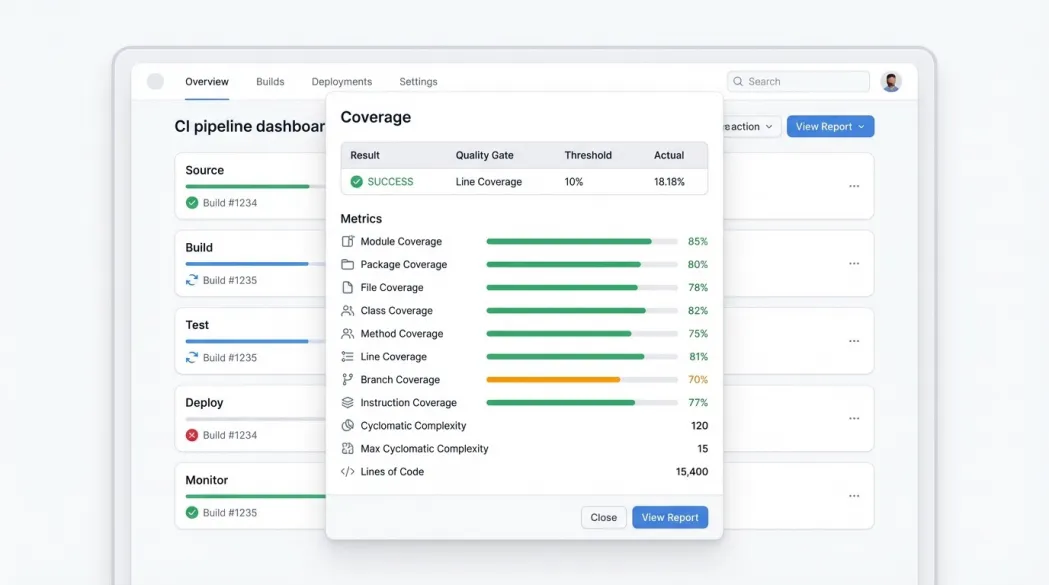
方案案例及效果
Unity由东亚银行(中国)有限公司完全独立自研、已获软件著作权与多项发明专利受理,其中软件著作权证书:

专利名称:单元测试代码生成方法、系统、设备及介质。状态(申请公布阶段)
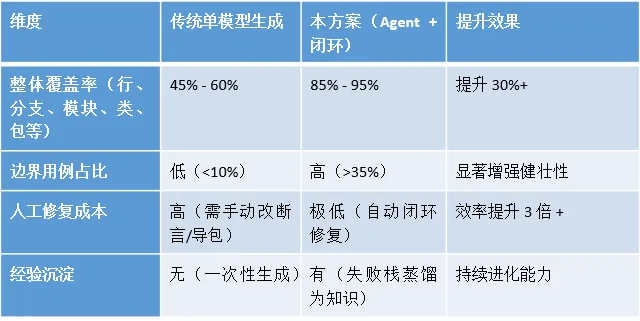
实施效果对比
方案未来展望
本方案虽然在单元测试生成领域取得了突破性进展,但技术的演进永无止境。基于当前的架构基础,我们规划了清晰的未来演进路线图,旨在进一步深化智能化水平与企业级适配能力。
动态权重学习与自适应检索: 未来将引入强化学习机制,让系统根据每次生成的 “最终采纳率” 自动调整检索算法的权重因子。这意味着系统将不再依赖预设的经验参数(如$\alpha, \beta$),而是能根据不同团队的代码风格,自适应地学习出最佳的检索策略,实现 “千人千面” 的推荐。
无监督失败栈蒸馏: 目前的 LoRA 微调依赖于一定量的标注或规则。未来计划利用无监督学习技术,自动从海量的 CI 失败日志中挖掘 “错误模式 - 修复代码” 对,自动训练轻量级修复模型,进一步降低对大模型的依赖,提升边缘端的修复响应速度。
企业级合规与审计增强: 随着 AI 监管的加强,我们将强化 “AI 生成审计” 功能。每一次代码生成、每一次 Prompt 构建都将被加密记录在案,形成可追溯的 “AI 生成及供应链安全报告”,协助企业满足 ISO 标准及行业监管要求。同时,深度融合质量门禁(Quality Gate),将 AI 生成的覆盖率指标直接作为发布的硬性阻断条件。