
方案概述
合合信息与兴业银行运营管理部、科技管理部和金融科技研究院联合成立项目组,在兴业银行智慧集中作业领域,基于“OCR+LLM+多模态理解+Agentic Coding”技术,通过智能化能力,在事前代替辅助和录入,事中代替辅助和审核,事后代替辅助和校验,极大的提高了集中作业平台的处理吞吐量和效率,实现了"人工依赖"到“人工辅助+AI驱动"的跨越式升级。
方案背景
业务痛点
在银行业数字化转型进程中,大部分业务已实现总行集中作业模式,这些业务通常包含事前录入,如按照模板填写文档内容信息;事中审核,如多个业务规则的数据校验,预警信息的配置审核;事后校验,如数据一致性完整性检查等标准流程,这些流程集中了大量简单重复且附加值较低的操作环节。
过去银行业一直在持续探索传统OCR技术在这些场景中的应用,试图实现自动化处理,然而仍面临如下困境:
1. 文档类型动态识别难
传统方法需预先定义文档类型并独立训练模型,与银行业务“先验类型未知、后验校验强依赖”的实际流程存在根本性矛盾。面对数十种文档混合处理需求,现有技术无法实现端到端分类-抽取-校验一体化,导致流程断点与效率瓶颈。
2. 非结构化版式泛化能力不足
合同跨页条款、票据可变模板、承诺书手写批注等非标准版式,超出传统OCR基于固定模板的解析能力。现有方案需针对每种版式重新标注训练,单次模型迭代平均耗时2-3周,难以满足业务敏捷性要求。
3. 长尾需求规模化覆盖难题
全国性银行机构面临分支机构地域差异化需求(如区域性政策文件、地方特色单据),传统方案需针对每个长尾场景投入数百标注样本,人力成本与时间成本呈指数级上升,亟需小样本学习(Few-shot Learning)及零样本迁移(Zero-shot Transfer)技术突破。
4. 模型能力提升难
由于行业内业务数据和模型语料分离的壁垒,不能结合实际业务作业过程中的问题进行快速调整,无法实现模型场景化能力的有效提升。
方案目标
1. 效率革新
在智慧集中作业的场景中将单笔业务处理时间缩短至10-20s,人力效率提升50%。在不增加业务人员的情况下,极大的提高单日的业务吞吐量。
2. 场景覆盖
以集中作业系统为标杆,扩展运管部其他业务场景以及零售贷款、信用卡及托管业务国际业务等场景。
3. 行业痛点破解
打破"数据孤岛"困局,构建银行业务全流程数据-模型闭环系统,解决传统AI方案中模型迭代滞后于业务变化的行业难题,模型版本迭代周期从行业平均3个月缩短至7天,通过持续的场景数据反馈,模型场景化识别准确率持续提升。
方案特点
特点1:相较于原集中作业中“两录一校”都是人工,当前借助AI智能录入,替代一录,辅助一录,人机协同高效作业
以电汇凭证处理为例:通过智能分类并自动识别票据类型和要素信息,能够替代一录完成提取和录入,无需人工干预;对于手写文字由OCR自动识别手写文字,识别不准的数据由人工补录修正。
双重校验:AI录入和人工补录的数据会进行比对,确保一致后,才提交至业务系统,保障数据准确性。
特点2-多场景、全要素抽取,兼顾短文本长文本
智能文档处理的整个方案,依赖的核心解析能力,支持双层PDF电子件、拍摄件、扫描件等不同格式的文档,手写体、印章、表格等不同类型的元素的智能抽取,兼顾短文本与长文本,能够输出版面元素,文档结构等,较准确的给模型以还原原始的数据结构,打好文档处理的坚实基础。
特点3-低样本快速适配
相较于传统分类抽取的模型训练需上百张以上的样本,当前方案通过embding向量化技术,单场景上传少量(10张左右)样本/分类关键字设置,无需标注训练,即可实现文档自动分类;对于复杂字段的抽取,借助多模态的语义理解能力,提供prompt和规则配置,在少量样本(10张左右)下仍能实现比较准确的抽取效果。
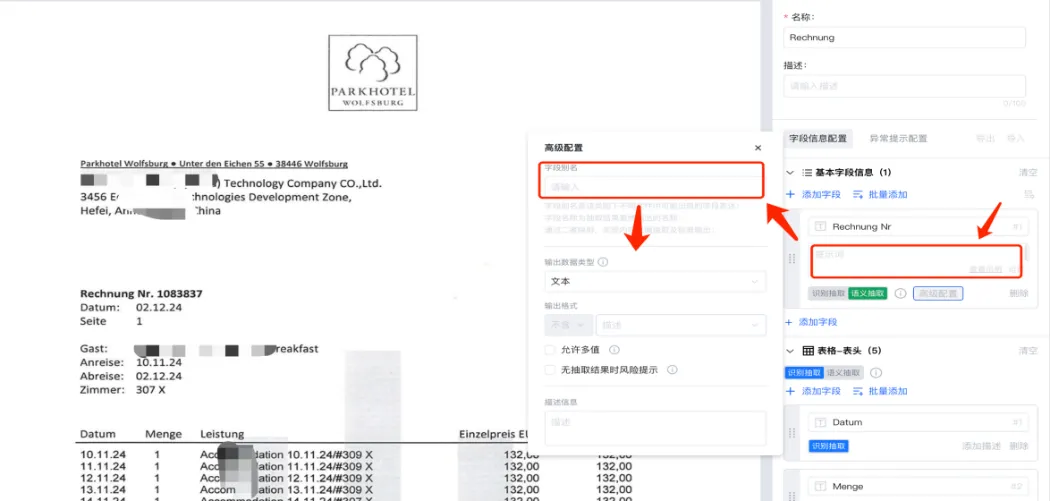
特点4-多模态模型的灵活组合与大小模型快速切换
系统内置多种小模型及预设字段,开箱即用,如通用卡证、国内通用票据等;对于业务场景要求的多种文档类型,小模型可与大模型同时灵活搭配,共同处理业务,兼顾效率与准确率。
特点5-模型全生命周期管理体系
- 物理隔离实验室环境,实现业务数据安全脱敏回流;
- 建立数据-模型-场景的三级权限管控机制,确保数据使用全程可审计;
- 支持多模态大模型(百亿参数级)与轻量化小模型(千万参数级)的并行训练;
- 首创"模型管道自助编排",支持根据业务场景特征自动组合最优模型方案,实现业务需求与模型能力的最优匹配;
- 简单场景:启用轻量化小模型,提升响应速度;
- 复杂场景:触发多模态大模型协同分析,保障准确率。
特点6- 方案基于大模型(AI)的Skill(技能)配置与管线(Pipeline)自动化生成技术,能够帮助开发者更高效地调整业务逻辑,并实现复用和调用
1、需求识别:明确输入、输出和业务规则(如文档字段提取);
2、AI配置:大模型自动生成初始处理管线(Pipeline)规则;
3、管线调试:开发者通过自然语言交互(Vibe Coding)微调逻辑;
4、固化部署:调试完成后,配置固化为Skill,支持后续复用。
方案业务流程图
文档处理流程图
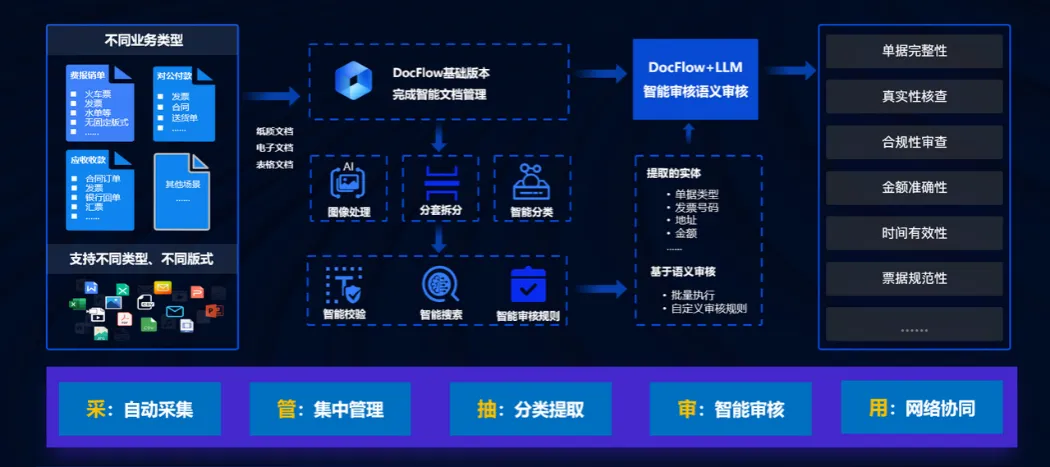
实现功能展示
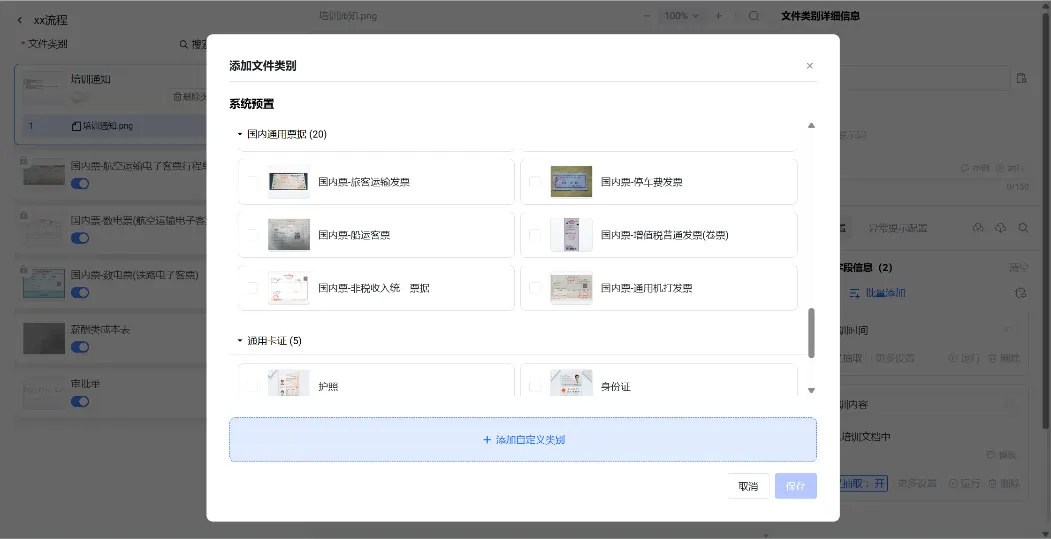
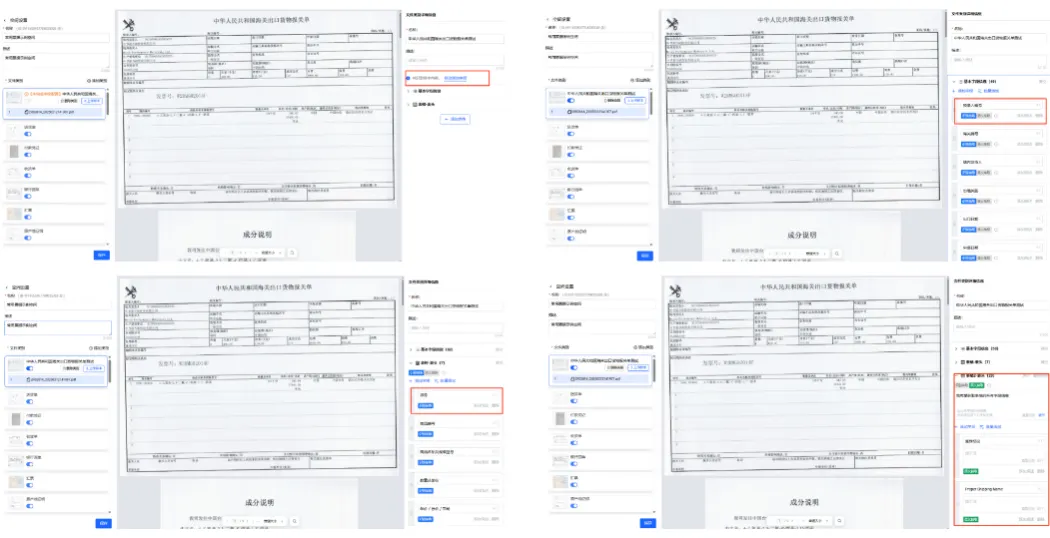
功能1-分类拆套引擎
分类依据:配置页面中每个文件类别上传的样本文件特征,并支持通过大模型对文件类型描述。上传文件至工作空间后,系统将会对其进行自动分类,分类完成后,可至对应文件类别下找到该文件。
拆套:若在上传时选择了文件拆分,系统将会分类到【多类别】,多类别的具体信息可点击该文件进行查看。
切分:若在上传时选择了多图切分,系统将会分类到【单页多图】,文件切分后的详细分类及抽取信息可点击该文件进行查看。
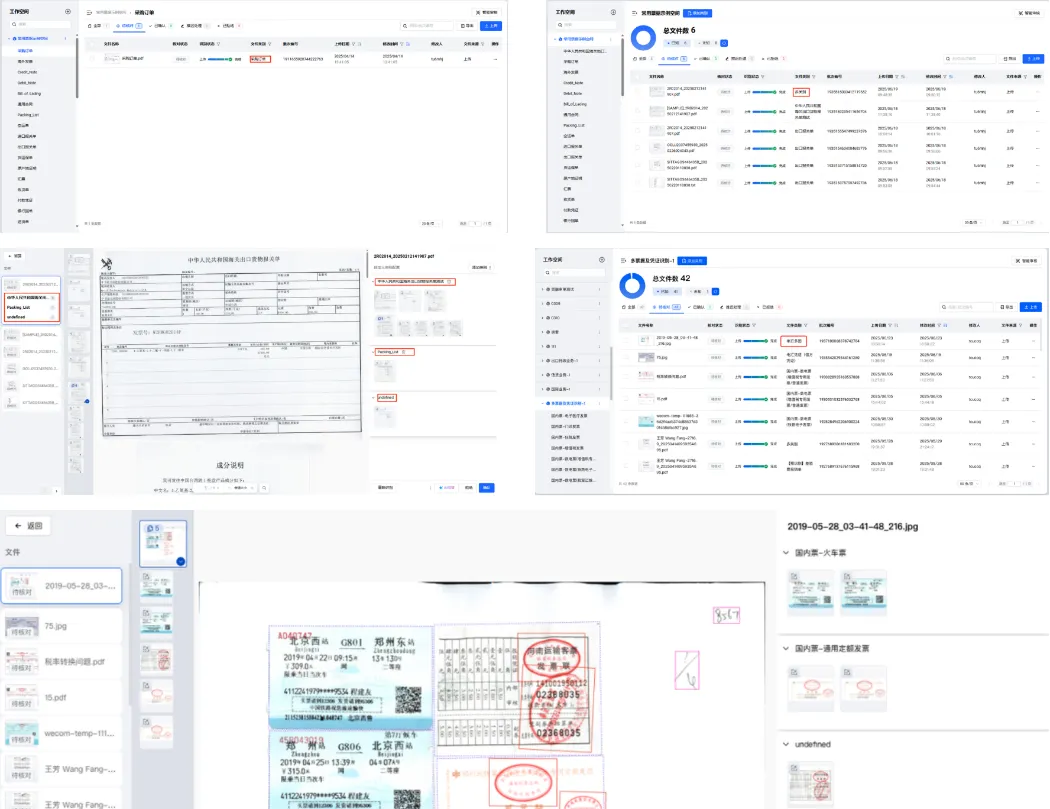
功能2-要素抽取的灵活配置可视化与审核结果可溯源
- AI识别样本内容,自动添加所需的抽取字段,人工对AI识别的字段进行增加、修改或者删除操作;
- 表格字段的配置抽取,可配置多表格抽取,提升抽取完整度;
- 通过写提示词描述抽取字段,提升抽取准确率;
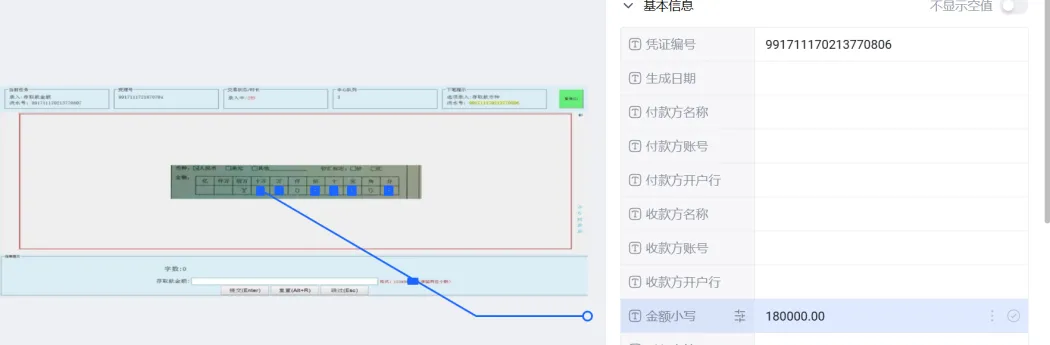
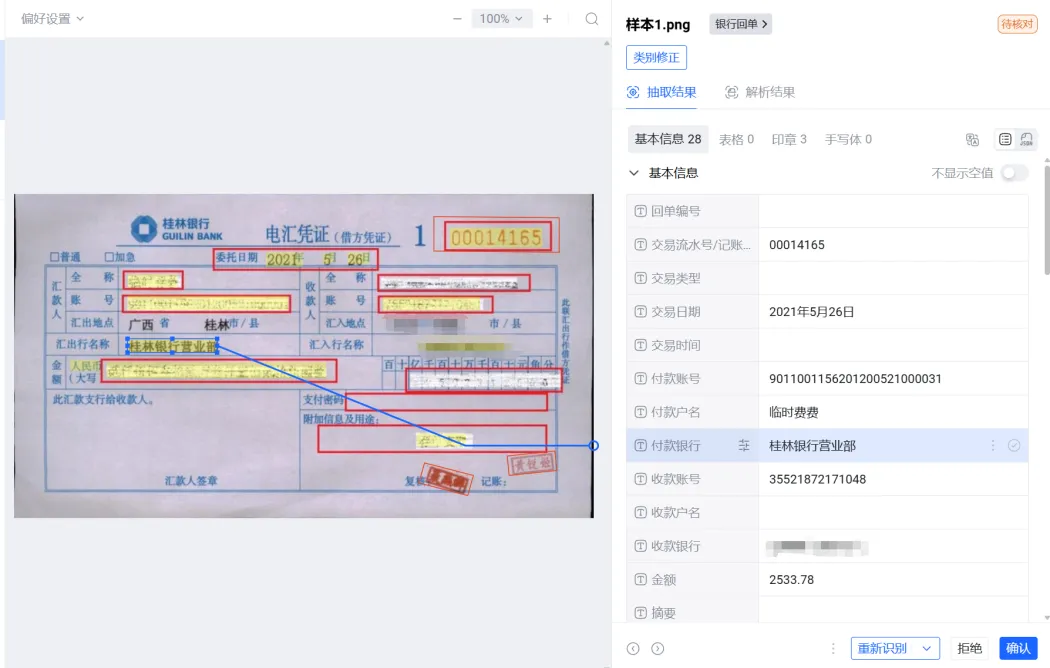
- 支持抽取结果、审核结果的原文定位可视化溯源,高亮定位抽取要素、审核要素、关键条款,并支持多文档的同屏展示,方便用户快速核对。
方案案例及效果
【集中作业平台建设的应用成效】
1、AI智能录入,替代一录,辅助一录,文档处理效率提升50%+;
2、高精度识别:关键字段准确率突破95%,显著降低人工复核成本,释放了人员效能,优化了整体的客户体验;
3、敏捷响应:科技人员建模开发提升效率80%,新文档类型适配周期平均缩短至0.2月,助力银行业务快速创新;
4、事后监督由AI替代人工进行全量业务定时跑批,自动比对校验人工复核问题数据,大幅增加了事后监督的覆盖面,降低了业务差错以及职务犯罪风险,极大提升事后监督的执行效率。
【规模化推广应用成效】
1. 规模化应用成效
多个扩展的业务场景实现AI全流程赋能。
2. 其他扩展场景的突破性表现
-在远程授权场景中,合照信息对比通过率超75%;
-在询证函处理中明细录入的替代率超94%,有效拦截前台录入错误笔数;
-在内部账务(复杂场景)中突破12类附件+手写签名的识别瓶颈,非结构化数据处理正确率超95%;
-在对公开户场景中,多个文档类型准确率超90%,开户时效从30分钟缩短至8分钟。
方案未来展望
未来,合合信息将与兴业银行一起围绕兴业银行行内场景,持续打造行内的AI智能集中作业企业级能力,构建结构化与非结构化数据智能化处理中枢,持续沉淀高质量业务数据,支撑AI模型迭代优化。通过业务数据回流,形成“数据→模型→场景→数据”的闭环飞轮,持续提升垂直场景的AI能力,覆盖更多的业务场景,赋能全行智能化。